

Editor’s note: This story is part of a series of articles produced by students taking NYU’s Media Law and Ethics class with a focus on generative artificial intelligence. Students were challenged to come up with novel uses for AI to advance the field of journalism.
Before we pick up a book to read, we take a look at its blurbs. For movies, we check their reviews. We don’t visit restaurants without checking their Yelp stars, or purchase items from online retailers without checking for manufacturing defects from prior purchasers. Even hotel rooms in cities half a world away have earnest prior visitors telling you what to expect (“Not enough storage!’” “The shower’s too hot!”) before you reserve.
So why must we launch into reading news articles sight unseen, unprepared, with a virgin mind, as it were?
Now, with Media Pedia, you no longer have to. A quick touch of a button and you get the lowdown on the article you are about to read. An executive summary. Some information about the writing quality and the level of difficulty. Thus forearmed, you can proceed.
A news article is an investment of time and attention: the two commodities most of us hamsters on the hamster-wheel of the internet have in short supply. Imagine a way of approaching the news where you get the main points instantly in a short paragraph crafted by a non-human intelligence. And I don’t mean aliens.
That’s right: Media Pedia leverages large language models, trained on trillions of bytes of verbiage that humans have laid on the Internet since it was invented. It leverages LLMs to read the article in question. Then, using its trillions of bytes of experience with human language, Media Pedia blurbs the article you are about to read.
I know what you’re thinking. Can we use Media Pedia to get around paywalls?
No, you cannot. Non-human intelligence it may be, but Media Pedia is quite humanistically ethical.
How it works
Media Pedia is a website.
Let’s say you are reading a news article on the internet you’d like to run by Media Pedia. It might be this one from the Washington Post of Aug. 2, a rather historic column by Ruth Marcus: Prosecuting Trump is perilous. Ignoring his conduct would be worse.
Screenshot of Washington Post
The user would click on the URL bar, where the internet address of the article is seen; copy the entire URL and paste it into Media Pedia’s box, and hit “go”:
Screenshot of Media Pedia
It will think for a few moments, during which time it consults LLMs. Then, it will blurb the article with a summary, a note on its objectivity, clarity, and level of sophistication.
In this case, Media Pedia gives the article very high marks for clarity (9/10) and also praises it for “conveying the gravity of the situation.” Marcus and the editors should be proud.
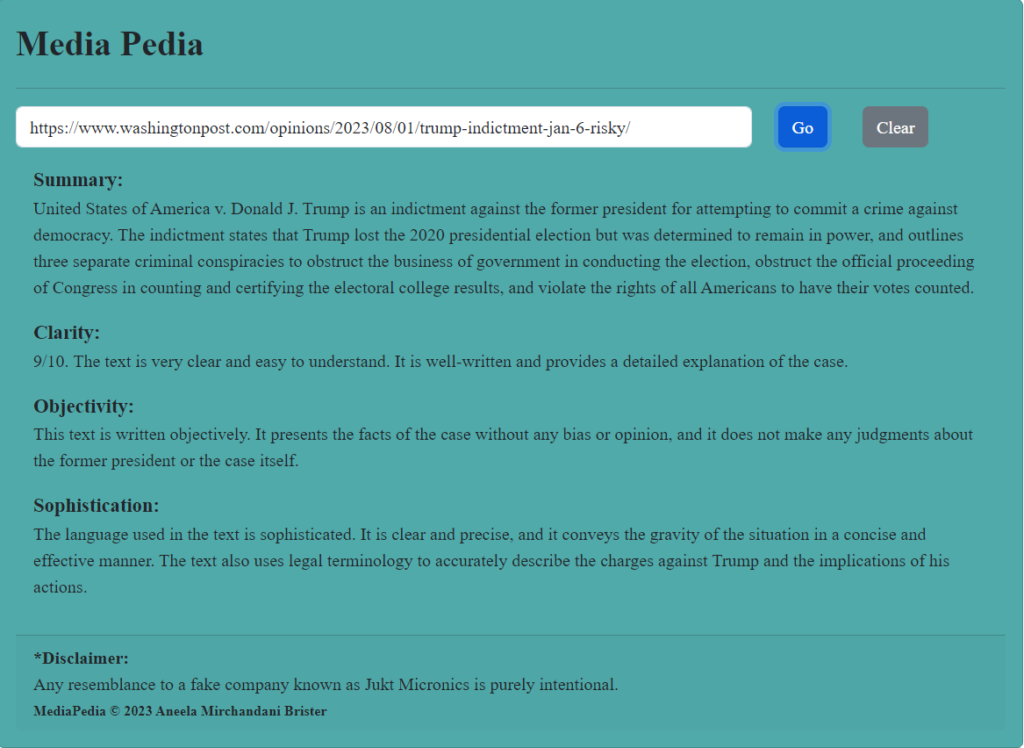
Screenshot of Media Pedia
When you’re ready to “pedia” another article, let’s say this one from Wonkette, dealing with the same historic moment: Trump-Defending Idiots: Free Speech is Dead. Jack Smith Killed It All, hit “clear” on Media Pedia and copy-paste this new URL. Hitting “go” tells you, for one, that the Wonkette article is not written objectively at all. It’s reasoning: the article calls Donald Trump a “lying scumbag,” which is subjective language. But it does praise the article for its use of metaphors and allusions!
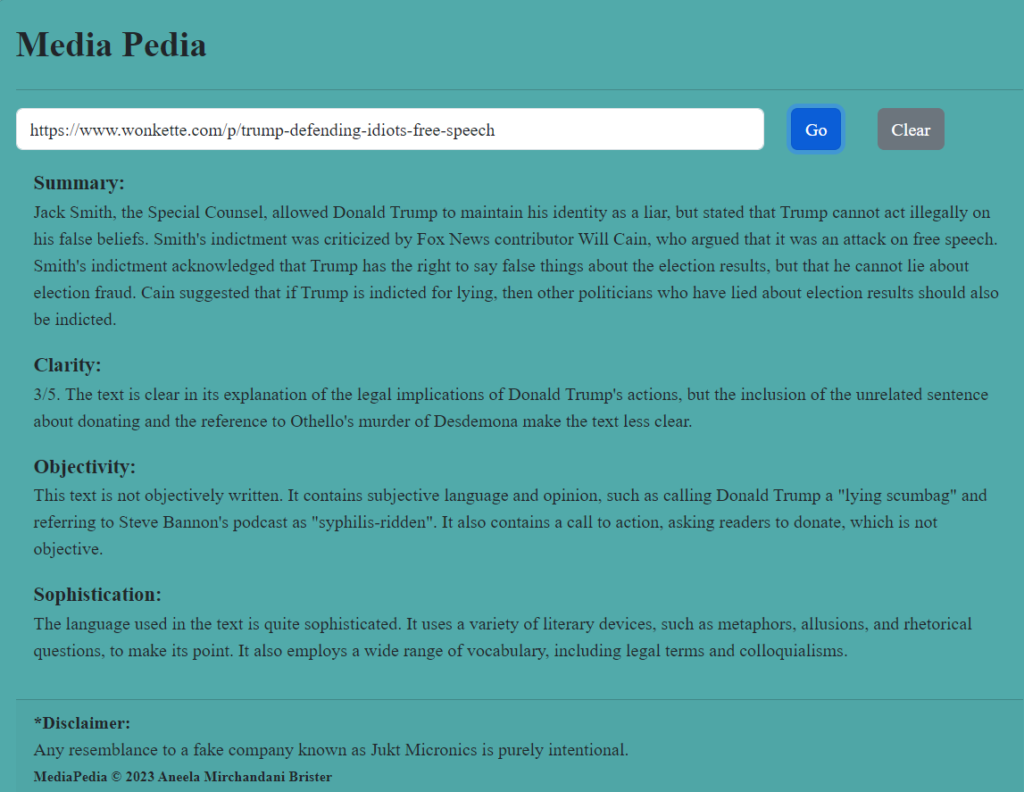
Screenshot of Media Pedia
How it works internally
For the technologically curious, here is a brief summary.
A website consists of two basic parts, the front-end and the back-end:
- The front-end: This is the part that you see, that shows on your browser window with the fancy colors and fonts and verbiage. The front-end runs on your computer, inside of the browser, whether it is Chrome, Edge, Safari, or other. Some examples of front-ends are below.
Screenshot of web pages
The front-end is coded in HTML, the universal language of producing the plain or snazzy web pages we see on the internet. It’s easy to look at the HTML running any page — while looking at any website, hit “ctrl+u”. A new page will open up, showing code. Up top, usually, you see an opening tag: “<html”. The rest of the HTML code follows.
The HTML is where programmers can have our own version of “fun”. I, personally, had a lot of fun making Media Pedia look like the legendary Jukt Micronics.
- The back-end: At the top of the front-end you see the URL: the text that starts with “http” and contains several slash characters and usually a “.com”, “.edu”, “.org” or other.

Screenshot of URL bar
The domain is the address of the back-end. It tells you where on the internet, which is global, the back-end lives — almost like the name of a city in the world. The back-end, or web server, is a program running on some computer on the internet, that is “serving” you your website, almost like a server at a table might ladle soup into your bowl.
Media Pedia has these same two parts. Its web server lives on Google Cloud, here: https://media-pedia-394501.wl.r.appspot.com/ . Its front-end lives on your browser, when you navigate to the URL above.
When you hit “go”, Media Pedia peeks at the HTML of the news article you are asking it to blurb. It picks up only the paragraphs from that article. This is the text within paragraph tags within the HTML, like this: <p>Some arbitrarily long or short paragraph</p>. It then takes that text, and asks AI some questions about it.
- LLM API: Media Pedia needs to call upon a third part: the large language model engine that is going to churn through the text of the article and blurb it. For this, it hooks into LangChain, a free platform for programmers, which allows a programmer to code a connection to a number of large language models commercially available today. I chose to have LangChain hook into OpenAI’s “text-davinci-003” model.
All the code is up on GitHub.
Limitations
While LangChain is free, OpenAI is not; and this brings us to our first limitation: cost. Each time we use Media Pedia we incur some fractions of a cent cost. It’s not much, but so far, for just one person, I have incurred $0.86. This can get pretty large for a real public website.
Another limitation is text size. The platform can only scan about 1,500 characters of the article. While still useful, it is by no means enough, and if this project were to become real, we would need to have AI read the entire article.
Lastly, we come to the limitations of the AI itself. While startlingly human-like, sometimes, AI’s non-human origins show. One might have noticed the somewhat nonsensical way it chose to explain the Wonkette article above: “Jack Smith, the Special Counsel, allowed Donald Trump to maintain his identity as a liar.”
If one has lived in the world as a human, this way of speaking of identity makes no sense. Then again, perhaps AI knows something we don’t?
Special Report: The AI-Augmented Journalist

November 13, 2023
A L(AI)tin America News Project
Social media content creation through automation and artificial intelligence, bringing news from Latin America to the English-speaking world.

November 10, 2023
Introducing, Let Us Find Out: An AI-Enhanced Reading and Learning Tool
What if a chatbot could help students develop critical reading skills?

November 2, 2023
Headline Hunt Trivia: Engaging Readers Like Never Before
What happens if you ask AI for a little help with headlines?

November 1, 2023
Automating Newsroom Translations with AI
ChatGPT and Zapier are tools news organizations should consider to help produce and share news.

November 1, 2023
Following the Tracks of Watergate Reporters Through an AI-Powered Escape Room
My experiences in creating a project for the AI-Augmented Journalist